In this article, I explore the application of LangChain in building AI agents, with a specific focus on drug safety reporting. Within the field of pharmacovigilance, LangChain could play a critical role in AI-driven extraction and summarization of adverse event reports, thereby improving drug safety monitoring. AI agents powered by LangChain can dynamically retrieve data, analyze patterns, and generate regulatory insights, streamlining the drug safety assessment process.
What is LangChain? LangChain is a framework for developing applications powered by large language models (LLMs). In essence, it provides a high-level, modular toolkit that makes it easier to build AI applications by chaining together different components around LLMs. This means you can connect language models with other utilities (like databases, APIs, or custom functions) in a sequence to achieve more complex tasks. LangChain’s design is extensible and unifies many capabilities of LLMs under one roof, implementing standard interfaces and integrating with numerous AI providers and tools. As a result, it simplifies the development process for LLM-based applications and promotes code reuse and maintainability.
Why is it useful? LangChain comes with a rich set of components and functionalities that cover everyday needs when building AI-powered agents. Developers can use LangChain to create chatbots, question-answering systems, text summarizers, and much more without starting from scratch each time. The framework handles a lot of the “boilerplate” of working with LLMs (like prompt management, model interfacing, and tool integration), allowing you to focus on the logic of your application. It offers both built-in components and third-party integrations, so you can easily connect to popular models (OpenAI GPT-3.5/4, Claude, etc.), data sources, and libraries. In short, LangChain provides a unified, flexible platform to harness LLMs for real-world applications, which is especially valuable given the growing complexity of AI model ecosystems.
Core Components and Functionalities: A LangChain-powered application typically uses several key components working in unison. Here are the core building blocks of LangChain and what they do:
- Prompt Templates – Templates for the text you send to the LLM. Prompts define how you ask the model to perform a task. LangChain provides utilities to create and format prompts effectively. (For example, a prompt template might be a question-answer format: “Question: {your_question}\nAnswer:”, where {your_question} is filled in at runtime.)
- LLMs (Language Models) – The AI models that generate text. LangChain supports various LLM providers (OpenAI GPT series, Hugging Face models, etc.) through a common interface. You initialize an LLM in LangChain (often with an API key for a service) and use it to get completions or chat responses. The LLM is the engine or “brain” of your agent, responsible for understanding prompts and producing answers.
- Chains – Logical sequences of operations that link together components (like prompts, LLM calls, and any post-processing). A chain defines a fixed workflow for the agent. For instance, an LLMChain in LangChain might take some input, format it with a prompt, call an LLM, and return the result. Chains can be simple (single prompt and model) or more complex (multiple steps, branching, etc.), but unlike agents, their sequence is hard-coded.
- Tools – External utilities or functions that the AI agent can use to assist in solving a task. Tools could include web search engines, calculators, databases, file loaders, APIs, or any functionality outside the language model. LangChain allows you to define and provide tools to an agent. The agent can then decide to invoke these tools for certain queries (e.g. use a web search tool to gather information or a calculator tool for a math question). Tools expand the agent’s capabilities beyond what it can infer from its prompt alone.
- Agents – High-level decision-makers that use LLMs plus optional tools to achieve goals. Instead of following a predefined chain of calls, an agent dynamically decides which actions to take and in what order. In LangChain, an agent will examine the user’s query, then potentially use tools (like searching data or looking something up) and the LLM iteratively, reasoning about each step. Agents are especially useful for building conversational assistants or complex workflows where the next step depends on intermediate results. (For example, an agent might receive a task, break it down, fetch information via a tool, and then use the LLM to compose an answer.) LangChain provides standard agent frameworks (such as the ReAct framework) that handle this decision-making loop for you.
- Memory – Mechanisms for the agent to remember information across interactions. If you’re building a chatbot or any agent that needs context from previous messages or prior data, Memory is essential. LangChain offers memory components that store conversation history or key facts so the agent can maintain context over time. This could be as simple as remembering the last user question or as complex as summarizing an entire dialogue so far. Memory helps create more coherent, contextually aware agents (for instance, a conversational agent that doesn’t forget what has been discussed).
Relevance for AI-Powered Agents: The above components make LangChain a powerful framework for developing AI agents. In traditional programs, you might have to manually code how an AI interacts with APIs or remember past inputs. LangChain provides ready-made structures for this. Notably, the agent abstraction in LangChain is what enables creating autonomous AI agents. An agent leverages an LLM to reason about tasks and can decide on the fly which tool or chain to. This is crucial for AI-powered agents that operate in more open-ended scenarios, such as virtual assistants or decision support systems. The agent can react to user requests by using tools to fetch data and then using the LLM to interpret or answer, all within one coherent framework. By handling the heavy lifting of integration (LLMs + tools + Memory), LangChain lets developers focus on defining the agent’s goals and providing the right tools, while the framework handles the orchestration. In summary, LangChain’s components work together to simplify the creation of intelligent agents that can perceive (via tools), think (via the LLM reasoning), and act (via issuing answers or executing tasks).
Use Case: Pharmacovigilance (Drug Safety)
Overview of Pharmacovigilance and Data Challenges: Pharmacovigilance (PV) is the practice of monitoring the safety of pharmaceutical drugs and taking action to reduce patient risks. It involves collecting and analyzing data on adverse drug reactions (side effects) and other drug-related problems to ensure medications remain safe in real-world use. Traditionally, PV relies on experts manually reviewing reports from various sources: clinical trial data, spontaneous adverse event reports (like those submitted to FDA or WHO databases), electronic health records, scientific literature, and social media. As healthcare usage grows globally, the volume of safety data has exploded – far beyond what manual methods alone can handle efficiently. Important safety insights might be buried in hundreds of case reports or scattered across different data streams.
Data Extraction and Summarization in Drug Safety: Given the sheer volume and diversity of data, pharmacovigilance professionals are turning to AI to help automate extracting and summarizing relevant information. AI can gather relevant safety data from a wide array of sources automatically, including patient records, email reports, social media posts, and scientific publications. For example, an AI system could scan thousands of drug safety reports for a particular medication and pull out key details (patient symptoms, outcomes, etc.) from each. However, raw extraction is only half the battle – making sense of the data is equally important. This is where summarization comes in. Summarization techniques (especially with LLMs) can condense large amounts of text or multiple reports into concise narratives highlighting the crucial points. Instead of a safety expert reading 50 detailed case reports about a drug, an AI agent could provide a one-page summary of common adverse effects, frequency, and patterns observed.
Such summarizations can greatly aid in signal detection – identifying potential safety issues early. AI-driven analysis can uncover hidden patterns or trends in adverse events that might not be obvious from individual reports. For instance, an AI might detect that numerous reports from different regions all mention a similar rare symptom for Drug X, signaling a possible emerging side effect. Large language models are particularly promising here: recent advances (e.g., transformer-based models like BERT and GPT) have made it possible to efficiently extract and analyze information from unstructured text sources like clinical notes or case narratives. A conversational LLM (like ChatGPT) can even be used to interactively query the data or generate summaries in real time, making it easier for stakeholders to access crucial safety information. AI-powered data extraction and summarization can boost pharmacovigilance by processing more data than humans could, standardizing reports, and quickly flagging the important details needed for decision-making.
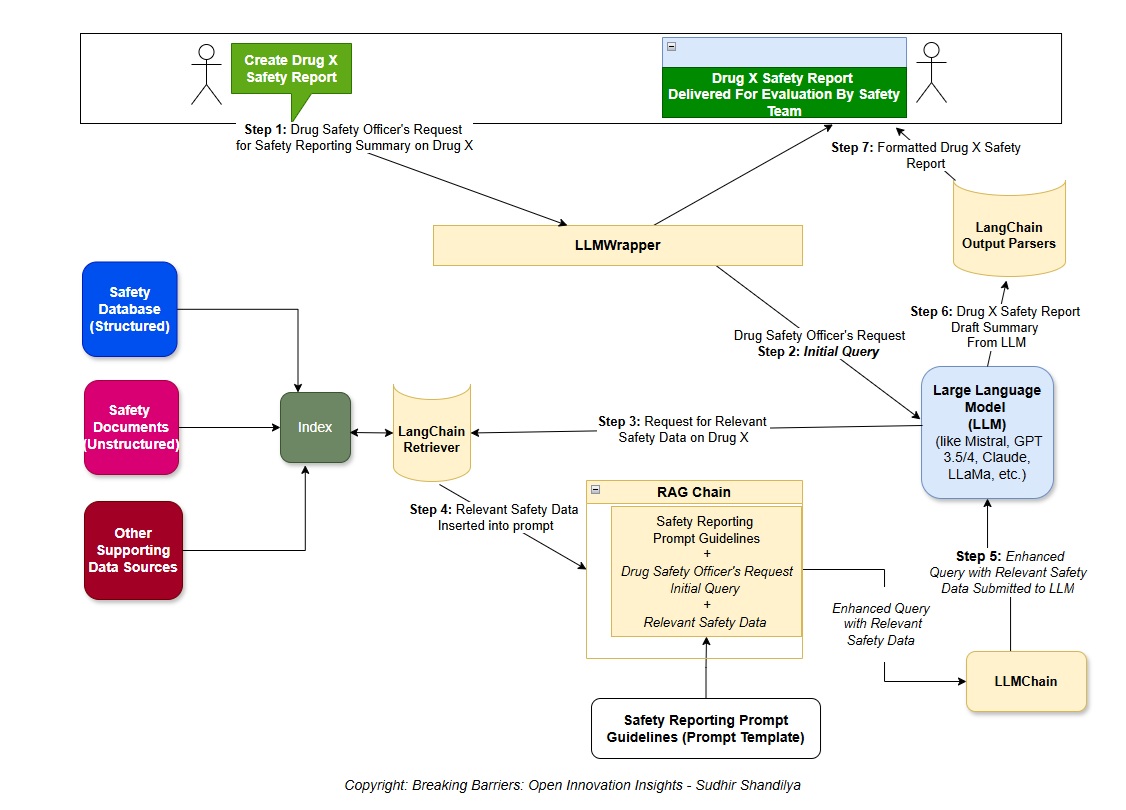
How LangChain Can Assist in this Domain: LangChain provides the tools to build an AI agent that automates parts of the pharmacovigilance workflow. Imagine a drug safety assistant that, given a drug name, can retrieve the latest safety reports and produce a concise summary for a safety officer. Using LangChain, you could design an agent with the following behavior:
(1) search a database or API for relevant adverse event reports (using a Tool, such as a web request or database query tool),
(2) compile or read those reports, and
(3) feed the information to an LLM to generate a summary of findings.
All these steps can be orchestrated within a LangChain agent. The benefit of using LangChain here is that it can manage the complexity of calling external data sources and LLM in a sequence under a unified framework. For example, you could use a Document Loader in LangChain to load drug safety bulletins or case report documents, then use a summarization chain or agent to have the LLM summarize the loaded text. The framework also supports chunking large texts and using Memory if you need to handle many reports in succession. In a pharmacovigilance context, a LangChain-based agent could automatically generate periodic safety update reports, create concise case summaries, or answer specific questions (e.g., “How many cases of liver toxicity have been reported for Drug Y in the past year?”) by combining database tools and LLM reasoning. By leveraging LangChain, developers in the drug safety field can prototype such AI assistants faster and ensure that the system’s components (data retrieval, parsing, summarization) work smoothly together. This leads to more efficient pharmacovigilance processes, where critical safety information is distilled and delivered promptly to those who need it.
Step-by-Step Guide for AI Agent Development
Let’s walk through a simple step-by-step process for developing an AI agent using LangChain. As our example scenario, we will use the pharmacovigilance use case (data extraction and summarization of drug safety information).
Step 1: Setting Up the Environment
Install Python and Required Libraries: Ensure you have Python 3.x installed on your system. You’ll also need to install LangChain and its dependencies. It’s recommended that this be done in a virtual environment. You can install the necessary packages via pip:
pip install langchain openai
(The langchain package will include the core LangChain functionality. The openai package is the OpenAI API client, required if you plan to use OpenAI’s LLMs.) Depending on your needs, you might also install other libraries (for example, pip install pandas if you plan to manipulate data or specific tool integrations offered by LangChain).
Obtain API Keys and Credentials: If you plan to use an LLM from a cloud provider (like OpenAI’s GPT-3.5/GPT-4), sign up for an API key. For OpenAI, go to their website and create an API key. Set up your environment with this key so LangChain can use it. For example, on Linux/Mac you can export it in the shell, or in Python you can set it as an environment variable. For instance: export OPENAI_API_KEY= “YOUR-API-KEY” in your terminal. It’s good practice not to hard-code secrets in your script. LangChain will read the OPENAI_API_KEY from the environment by default. (If you use other services or tools that require keys – like SERP API for search – get those credentials as well.)
Basic Configuration Check: Once installed, it’s helpful to do a quick check. Run a Python REPL or script and try importing LangChain and ensuring the version is correct. For example:
import langchain
print(langchain.__version__)
This step ensures everything is installed properly before moving on. Also, ensure you have an active internet connection if your LLM or tools need to call external services (the OpenAI API call, for example, requires internet access).
Step 2: Designing the Agent with LangChain Components
Before writing code, it’s important to plan out the agent’s design. Consider what the agent needs to do and which LangChain components are appropriate:
- Define the Task: In our case, the task is to extract and summarize pharmacovigilance data. To simplify, we might frame this as: “Given some drug safety text (like a collection of adverse event reports or a summary from a database), produce a summary of the important points.” This is essentially a text summarization task with domain-specific content.
- Choose the Components: A straightforward approach is to use a Chain (rather than a full Agent with multiple tools) for a summarization task. Specifically, an LLMChain can handle this: it will take input text, plug it into a prompt, and get a summary from the LLM. The core components we will use are:
- An LLM (the language model that will generate the summary). We’ll use OpenAI’s GPT-3.5 in this example for its strong natural language capabilities.
- A Prompt Template that instructs the model to produce a summary of the input text.
- The LLMChain to tie the prompt and model together into a single callable sequence.
In a more complex scenario, we could introduce Tools and an Agent executor if the agent needed to search for data or perform multiple steps (e.g., fetch the latest reports first, then summarize). For clarity, we’ll keep this example focused on the summarization step, assuming the data is already provided to the agent. (Later, you can extend this design to have a tool for data retrieval if needed.)
- Consider Memory (if needed): For a one-shot summarization, we do not need a memory component because each task (summarizing a batch of text) is independent. Memory is more relevant for conversational agents or agents that handle multiple coherent dialogues or continuous sessions. We can proceed without adding Memory to our chain.
- Plan Inputs/Outputs: Decide how the agent will receive data and return results. In our design, the input will be a chunk of text (e.g., a drug safety report or a collection of adverse reaction descriptions), and the output will be a summarized version of that text. We should also consider the output format (plain paragraph summary, bullet points, etc.) and include that in the prompt instructions if desired.
With this design in mind, we can proceed to implementation. We will build a function (or script) that takes a piece of pharmacovigilance text and produces a summary using LangChain.
Step 3: Implementing the AI Agent (Extraction & Summarization)
Now let’s implement our simple AI agent step by step. We will do this in Python, using the LangChain framework and OpenAI as the LLM backend. The agent (chain) will take a sample pharmacovigilance report text and output a summary.
Implementation Steps:
- Set up the Python script or notebook: Start by importing the necessary classes from LangChain (e.g., LLMChain, OpenAI, PromptTemplate). Also, import OS if you plan to access environment variables for the API key.
- Configure the OpenAI API key: Ensure the API key is available. You can either set it via os.environ[“OPENAI_API_KEY”] in the code or rely on it being exported in your environment. We’ll show it in code for completeness (using a placeholder for security).
- Prepare the input data: This could be fetched from a file or API, but for this demo, we will use a hardcoded example string that represents drug safety information. (In practice, you might load actual data here, such as reading from a CSV of adverse events or querying a database.)
- Create a prompt template: We must tell the LLM what to do. The prompt could be something like: “Summarize the following report… [report text] …”. We’ll use LangChain’s PromptTemplate to create a template with a placeholder for the report text.
- Initialize the LLM: Set up the OpenAI LLM through LangChain. We specify the model (e.g., “text-DaVinci-003” or a chat model like “GPT-3.5-turbo”) and any parameters like temperature (which controls creativity vs. determinism of the output).
- Create the chain: Use LLMChain to tie the prompt and LLM into a single object that can process our input and return a result.
- Run the chain on the input data: Call the chain with our pharmacovigilance text. This will send the prompt (with the inserted text) to the LLM and get a summary back.
- Output the summary: Print the result to verify the agent’s output. In an application, post-process this, log it or return it from a function or API.
We’ll illustrate these steps in the code next.
Code Example
Below is a well-structured Python script demonstrating a simple data extraction and summarization agent using LangChain. The code is heavily commented on to explain each part. This example assumes you have installed LangChain and the OpenAI package and that you have your OpenAI API key ready.
# 1. Import necessary libraries and classes from LangChain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
# 2. Set up the OpenAI API key
# In practice, prefer to set this in your environment via secured config.json. Here we use a placeholder for a demonstration.
os.environ[“OPENAI_API_KEY”] = “YOUR_OPENAI_API_KEY” # Replace with your actual OpenAI API key.
# 3. Prepare the pharmacovigilance data (the text to be summarized).
# This text might come from a database or file in a real scenario. Here, we use a sample report string.
drug_safety_report = “””
According to the FDA Adverse Event Reporting System, the drug X has been associated with 50 cases of severe skin reactions
and 10 cases of acute liver failure reported between 2018 and 2021. Patients often presented with rash, fever, and elevated liver enzymes
within 2-6 weeks of starting the medication. In several instances, symptoms improved after discontinuation of X.
Regulatory agencies have issued warnings to monitor patients for signs of liver injury and advise immediate drug discontinuation if such signs appear.
“””
# 4. Define a prompt template for summarization.
prompt = PromptTemplate(
input_variables=[“report”],
template= “You are a pharmacovigilance AI assistant. Summarize the key safety findings from the following report:\n\n{report}\n\nSUMMARY:”
)
# The prompt instructs the model to act as a drug safety assistant and summarizes the report provided.
# 5. Initialize the OpenAI LLM (Large Language Model) with desired parameters.
# For this example, we’ll use a GPT-3 model (text-davinci-003). The temperature is set to 0.7 to balance clarity and creativity.
llm = OpenAI(model_name=”text-davinci-003″, openai_api_key=os.environ[“OPENAI_API_KEY”], temperature=0.7)
# 6. Create an LLMChain that binds the prompt template and the LLM together.
chain = LLMChain(llm=llm, prompt=prompt)
# 7. Run the chain on the input data to get the summary.
summary = chain.run(report=drug_safety_report)
# 8. Print out the summary result.
print(“Generated Summary:”)
print(summary)
Explanation of the Code:
- We first import OpenAI, PromptTemplate, and LLMChain from LangChain. These correspond to the planned components: the language model, the prompt, and the chain that ties them.
- We set the OpenAI API key using os.environ. LangChain will use this key under the hood when the LLM is called. (Make sure to replace “YOUR_OPENAI_API_KEY” with your secret key; do not publicly share this key.)
- The drug_safety_report string is a placeholder for whatever pharmacovigilance data you have. In this example, it’s a fictitious report about a drug (“X”) with some adverse events. This text includes the kind of information a pharmacovigilance expert might see: number of cases, types of reactions, timing, outcome, and regulatory advice.
- The PromptTemplate is constructed with a template string: “You are a pharmacovigilance AI assistant. Summarize the key safety findings from the following report: … {report} … SUMMARY:“. We give it one input variable report, which will be replaced with the actual report text when we run the chain. This prompt guides the LLM to produce a concise summary focusing on safety findings.
- We initialize OpenAI with the model name and our API key. We choose text-davinci-003 as a general-purpose powerful model. (We could also use GPT-3.5-turbo via the ChatOpenAI class for a similar or even more cost-effective result, but that would involve a slightly different usage pattern. For simplicity, the completion model is used here.) The temperature=0.7 means the output might be somewhat varied if run multiple times; if we wanted the most deterministic summary, we might set the temperature to 0.
- We then create an LLMChain by passing in the llm and prompt. This chain knows how to take a report input, format the prompt, call the LLM, and return the result.
- chain.run(report=drug_safety_report) executes that sequence. We pass the drug_safety_report text to the chain (matching the report variable in our prompt template). Under the hood, LangChain will construct the full prompt and invoke the OpenAI model to get a completion.
- Finally, we print the generated summary. If everything is set up correctly and the OpenAI API call succeeds, we should see a concise summary of the safety information from the report.
Expected Output: The output will be a paragraph (or a few bullet points) summarizing the key points from the input text. For example, the summary might say something like: “X has been linked to serious adverse effects, including about 50 cases of severe skin reactions and 10 cases of acute liver failure since 2018. Symptoms (rash, fever, elevated liver enzymes) typically appear within the first 2–6 weeks of treatment. Many cases resolved after stopping the drug. Regulators advise close monitoring of liver function and immediate drug discontinuation if signs of liver injury occur.” (This is a hypothetical output paraphrasing the input – the actual wording might differ, but it should convey the same facts.)
Modify the drug_safety_report text or the prompt to experiment. For instance, you could add multiple reports together and ask for a combined summary or change the tone of the summary. The LangChain LLMChain abstraction will handle the interactions with the model for you, so you can focus on the content of what you want summarized.
Where and How to Deploy Your LangChain Agent
Once your AI agent (or chain) is working correctly in a development environment, you have several options to deploy it and make it accessible to end-users or other systems. Here are some common deployment scenarios and best practices:
- Local Deployment: You can run the agent on your local machine or a private server as a script or application. This is suitable for personal use, internal company tools, or prototyping. For example, a pharmacovigilance team might run the summarization agent on local data as needed. Running locally gives you full control and privacy (especially if the data is sensitive), but it may not always be online or scalable to many users. You might schedule a Python script to run daily, summarizing new reports and saving the results to a file or database.
- Cloud or Server Deployment: To serve multiple users or integrate the agent into a larger system, deploying on a server or cloud platform is ideal. You could host the agent as a cloud VM (on AWS, Azure, GCP, etc.) or container services like Docker/Kubernetes. For instance, you could containerize the application (so it includes all dependencies and environment setup) and deploy that container on a cloud server. This allows the agent to run continuously and handle requests as they come. Ensure that you securely provision your API keys on the server (using environment variables or secrets management) and that the server has the necessary computing resources. Heavy computation happens on their side if using OpenAI or other external LLMs, so your server mainly needs to handle I/O and any pre/post-processing.
- Expose as an API Service: One common way to deploy an AI agent is to wrap it in a web service (REST API or GraphQL). Using a web framework like FastAPI or Flask in Python, you can create an endpoint (e.g., /summarize_report) that runs your LangChain agent and returns the summary when called with some input data. This turns your agent into a service that other applications can call. For example, a pharmacovigilance dashboard could call this API to get on-demand summaries of new reports. Make sure to implement proper error handling (for cases where the LLM fails or times out) and possibly request authentication if the API is for internal use. LangChain agents can also be deployed as background workers that listen to tasks (using a job queue system) if real-time API response isn’t needed.
- Web Interface (UI) Deployment: If you want non-technical users to interact with the agent, consider building a simple web interface. Tools like Streamlit or Gradio allow you to create a quick web app around your agent with minimal code. For example, you could make a small web app where a user uploads a pharmacovigilance report (or enters a drug name to fetch data), and the app displays the summary generated by the LangChain agent. This approach is user-friendly and good for demos or internal tools. Just be mindful of the latency (LLM calls take a few seconds) and inform the user to wait for the result.
- LangChain-Specific Deployment Solutions: The LangChain ecosystem is evolving, and there are emerging options to deploy and manage agents more seamlessly. For example, LangChain has introduced LangSmith and LangGraph tools for monitoring and deploying applications. With minimal hassle, the LangGraph Platform can turn your LangChain agent into a production-ready hosted API or even a chat assistant. These services can manage scaling and versioning and even provide interfaces for human feedback. While these might be more advanced than needed for a beginner, it’s good to know such options exist as you grow your project. They can simplify deployment in the long run by offering a managed environment specifically for LangChain apps.
Maintenance and Improvement: Deploying your agent is not the end of the journey. Maintaining and improving it over time is crucial, especially in a domain like pharmacovigilance, where data and requirements continuously evolve:
- Monitoring and Logging: Always log the agent’s interactions and outputs (while respecting privacy and compliance if dealing with sensitive data). Logs help you identify issues, such as prompts that lead to poor summaries or errors from the LLM API. Monitoring tools (including LangSmith or custom logging) can track usage, latency, and errors. For instance, keep track of how often summaries need manual correction—this could indicate where the agent might need improvement.
- Iterative Prompt Tuning: The quality of the agent’s output can often be improved by refining the prompt or adjusting LLM parameters. If you notice the summaries are missing key details or are too verbose/too brief, you can tweak the prompt instructions (e.g., “include statistics in the summary” or “keep the summary under 100 words”). Because LangChain makes prompts modular, updating the prompt template in your deployed app is straightforward. Continuously gather feedback from users (or domain experts) about the summary quality and adjust accordingly.
- Updating Data Sources: In pharmacovigilance, new data sources or updated reports may become available over time. Make sure your agent can handle new formats or that you update the data ingestion part (the Tools or loaders) to accommodate changes. For example, if a new database of adverse events is introduced, you might need to add a tool to query it or adjust the parsing logic for the agent.
- Scaling and Performance: You should scale the deployment as usage grows. This could mean running multiple instances of your service or optimizing how you call the LLM (for example, batching requests if you have many to do or caching results for repeated queries). Keep an eye on the costs as well – using an LLM API incurs usage fees. You can mitigate this by using smaller or open-source models for less critical tasks or by setting limits on how large an input the agent will summarize (maybe splitting very large texts into smaller chunks).
- Stay Updated with LangChain: LangChain is an active project with frequent updates and improvements. New features (or changes) could benefit your agent. Occasionally review the LangChain documentation or release notes for updates that might, for example, introduce a more efficient summarization chain or better integration with a data source you care about. However, also be cautious with updates in a production system – test new versions of LangChain in a development environment to ensure nothing breaks before rolling them out.
Following these deployment and maintenance practices ensures that your LangChain-based AI agent remains reliable, secure, and effective over time. Whether helping pharmacovigilance professionals stay on top of drug safety data or powering another AI-driven application, the combination of LangChain’s framework and thoughtful deployment will set you up for success.