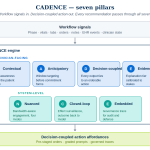
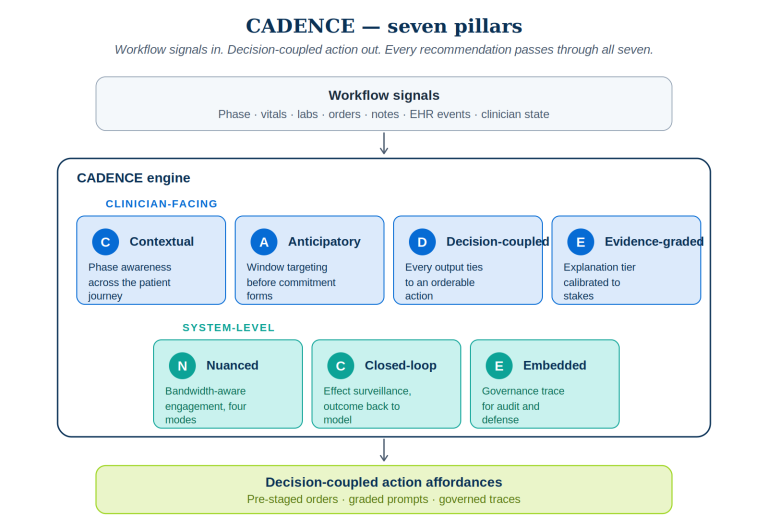
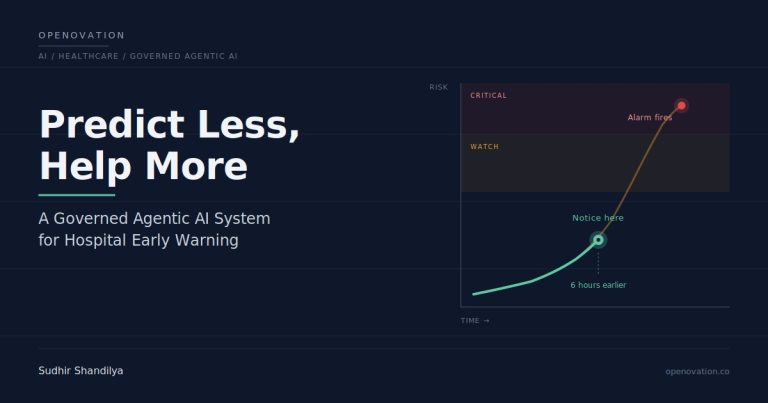
In the dynamically evolving world of technology, data science has crystallized into a pioneering frontier, commanding immense demand in various professional sectors. It has become an amalgamation of skills and knowledge bases, technical and non-technical alike, necessary to decipher hidden value from raw data. Given the rapidly growing influence and employment opportunities in this field, many are arduously contemplating ways to advance from being a professional to becoming an expert data scientist in the most efficient way possible. This transformation demands persistence, a comprehensive probe into several areas, and a rigorous yet creative learning strategy to grasp and apply the necessary concepts proficiently within 21 days. Please note that this blueprint to learning assumes you have some programming background and understanding of the software engineering and development concepts.
Math and Statistical Knowledge
Understanding Data Science
Data science is a multidisciplinary field that uses data to generate insights, make predictions, decisions, and design strategies. It combines various fields, including mathematics, computer science, statistics, and business analytics. To become a proficient data scientist, focus on these areas as they provide the baseline knowledge and skills vital for data science.
Grasp Mathematics and Statistics
The first step to becoming a data scientist is having a solid understanding of mathematics and statistics. Topics you should become proficient in include calculus, linear algebra, probability, and statistics. These areas provide the foundation for more advanced concepts like machine learning and artificial intelligence, where you’ll analyze and interpret complex data sets.
Learning Coding Languages
Becoming a skillful data scientist also requires some programming knowledge. Python and R are two popular languages in data science due to their robustness in handling large amounts of data. Other important languages include SQL, which is used for data extraction, and Java and C++, which are used for system-based data analysis.
Mastering Data Analysis and Visualization
Aside from programming, building your data analysis and visualization skills is crucial. These skills involve cleaning, processing, and analyzing data to reveal actionable insights. Tools like Tableau and Power BI are popular for data visualization, while Pandas and NumPy are used for data analysis.
Exploring Databases
A proficient data scientist needs to learn how to manage and manipulate databases. Therefore, you should familiarize yourself with database querying languages like SQL and database systems like PostgreSQL and MySQL. Understanding NoSQL databases like MongoDB will also be valuable as they can handle unstructured data.
Dive into Machine Learning and AI
At the more advanced end, machine learning and artificial intelligence are major areas in data science. Machine learning uses algorithms to identify patterns, make predictions, and learn from data, while artificial intelligence involves creating intelligent systems that can perform tasks like a human. Code libraries such as Scikit-learn and TensorFlow are frequently used resources in these areas.
Attain Soft Skills
Aside from technical skills, data scientists need soft skills. Critical thinking is required to make sense of complex data and make informed decisions. Communication skills are also vital for explaining technical concepts to non-technical teams.
Ongoing Learning and Practice
Continuous learning and practice are critical to keep up with the rapidly changing field of data science. Utilize online learning platforms, attend workshops and conferences, and involve yourself in projects that allow you to apply your skills. After 21 days of dedicated learning and practice, you will have laid solid groundwork for becoming a data scientist.

Programming Skills – Python/R
Getting Started with Python and R for Data Science
The first step towards becoming a data scientist is getting acquainted with the primary programming languages in the field – Python and R. Both languages are extensively used in data science, and understanding their functionalities and applications is fundamental. Python and R have ample resources available online for self-learning. Codecademy, Coursera, and Khan Academy are some online platforms where you can begin learning these programming languages. Dedicate at least an hour each day to learning and practicing these languages.
Data Wrangling and Manipulation
In data science, data wrangling is the process of cleaning, structuring, and enriching raw data into a desired format for better decision-making. Similarly, data manipulation involves altering data to make it easier to read and analyze. The pandas library in Python is a powerful data manipulation and analysis tool. On the other hand, the reshape2 and dplyr packages in R are widely used for data wrangling tasks. Allocate your second week towards understanding and practicing these skills, using real-life data sets for hands-on experience.
Mastering Data Visualization
Data visualization is vital to understanding trends, outliers, and patterns in data. It involves the presentation of data in a graphical or pictorial format. Python offers multiple data visualization libraries, such as Matplotlib and Seaborn, where you can generate line plots, scatter plots, histograms, bar charts, and much more. In R, ggplot2 is a powerful tool for producing sophisticated and professional graphical representations. During the third week, focus on learning and experimenting with these visualization tools. It is also essential to understand the proper visualization for each data and analysis type.
Getting Hands-on with Real Projects
After acquiring fundamental Python, R, and data analysis knowledge, it’s time to apply these skills through projects. You can find datasets of interest on websites like Kaggle to test your skills. Start with simple projects, gradually moving to more complex ones. This real-world application during the last few days of the 21 days would give you the confidence to solve real-world problems using data science.
Keep Learning and Practicing
Although it’s challenging to become proficient in data science in just 21 days, this period can be used to set a strong foundation in the field. Remember, data science is a vast domain that requires continuous learning. Participate in online coding challenges, attend webinars, and follow top data scientists on professional networks to stay updated. Applying what you learn practically is key to mastering data science. As you grow in the field, consider specializing in a specific industry or type of analysis to enhance your data science skills further.
Machine Learning
Understanding Data Science Basics
Before you dive into the world of data science, it’s crucial to understand its basic terms and concepts. Start by learning about databases, SQL and NoSQL, and software coding, primarily in Python and R. These are integral parts of the data science architecture. It would help to familiarize yourself with descriptive statistics concepts, including mean, median, variance, standard deviation, and correlation.
Exploring Machine Learning
Machine learning is at the heart of data science, enabling you to make accurate predictions or automated decisions. There are three types of machine learning you should know:
- Supervised learning, where you train the model using labeled data.
- Unsupervised learning, where the model looks for patterns in an unlabeled dataset.
- Reinforcement learning, where you train your model to make sequences of decisions.
Learning Relevant Algorithms
Specific algorithms are associated with each type of machine learning. Start by understanding the Linear Regression and Logistic Regression for Supervised Learning. For Unsupervised learning, comprehend clustering methods such as K-means. In Reinforcement learning, learn about algorithms like the Monte Carlo Method and Temporal Difference (TD) method.
Mastering Data Cleaning and Visualization
No dataset is perfect. Learning how to clean datasets and handle them using techniques such as imputing missing values or predicting them via machine learning is essential. Furthermore, learning tools like Matplotlib, Seaborn, or Plotly for data visualization will help show your findings in an easily digestible manner.
Exploring Advanced Machine Learning Concepts
Once you’re comfortable with basic machine learning, dive into more advanced concepts. Learn about Natural Language Processing and how to train models to understand text. Understand the principles of Deep Learning and how it differs from traditional machine learning.
Practicing with Real Projects
Finally, start working on real-life projects to get practical experience. Websites like Kaggle provide numerous datasets that you can explore. You can participate in competitions that challenge your new skills and offer potential career exposure.
Learning the Techniques of Big Data
We live in an age of big data, and data scientists must know how to handle voluminous amounts of data on cloud-based platforms. Concepts like MapReduce and Hadoop will be essential to understand.
Keeping Up with Continuing Education
The world of data science is constantly evolving. Therefore, keeping up with the latest trends and technologies is a must. Dedicate daily time to reading news, blog posts, and academic papers to stay updated.
Every person has a different learning pace, so the 21-day timeframe suggested here is just an indication. Remember to be patient with yourself and enjoy learning data science.
Data Wrangling and Visualization
Day 1-3: Getting Started with Basic Concepts and Tools
To begin your learning, you must familiarize yourself with the basics of data science tools. Learn Python, the most popular language for data science, along with libraries like Pandas for data manipulation and analysis. Explore NumPy, which offers comprehensive mathematical functions, and random number generators, and has tools for integrating C/C++ and Fortran code.
Day 4-6: Understanding and Implementing Data Wrangling
Data Wrangling is the process of cleaning, structuring, and enriching raw data into a desired format for better decision-making in less time. With Python’s Pandas library, you can filter and modify the data per the requirements—practice by dealing with missing data within a data set or by replacing values. Manipulate data using techniques like Merging, Reshaping, Slicing, etc.
Day 7-9: Visualization using Matplotlib and Seaborn
Visualization is crucial to understanding data and is paramount in explaining the results to non-tech business leaders. Python’s Matplotlib is a plotting library with a lot of functionality for data visualization. Begin by creating basic plots like lines, bars, and histograms, and then move on to more advanced plots like scatter plots, stack plots, and pie charts. Seaborn builds on top of Matplotlib and introduces additional plot types. It also makes your traditional Matplotlib plots look prettier.
Day 10-12: Advanced Data Wrangling and Visualization
Continue practicing with Pandas, Matplotlib, and Seaborn by taking on more complex datasets and trying to extract meaningful insights. Try cleaning a dataset with many missing values or making a beautiful heatmap with Seaborn.
Day 13-15: Start Learning R and ggplot2
R is a programming language and free software environment for statistical computing and graphics. Begin by installing R and getting familiar with its basics, including factors, lists, and data frames. Ggplot2 is an R package for data visualization, producing stunningly beautiful graphics. Try creating different visualizations like scatter plots, bar plots, line plots, histograms, box plots, etc.
Day 16-18: Understanding and Implementing Data Wrangling in R
Like Python’s Pandas, dplyr is an R package that provides tools for efficiently manipulating datasets. It includes various easy-to-use functions, and the operators can be chained together using the pipe operator %>% to perform complex operations.
Day 19-21: Advanced Data Wrangling and Visualization in R
Practice the skills learned in R, ggplot2, and dplyr with more complex datasets. Learn to manage larger datasets to build resilience and flexibility in your coding skills. Challenge yourself in data wrangling and visualization with this new set of tools.
Remember, learning a new skill and becoming proficient takes time and practice. Consistent learning and persistently implementing your knowledge on projects can lead you to become an efficient data scientist in 21 days.
Big Data Processing
Understanding Big Data and Its Importance
Big data is a large volume of structured or unstructured data which can be analysed computationally to reveal patterns, trends, and insights. These insights can later be used for making strategic decisions. Big data is critical today because it enables companies to improve their operations, provide better customer services, create personalized marketing strategies, and increase profitability.
Big Data Tools Overview: Hadoop and Spark
Hadoop and Spark are two of the leading big-data processing frameworks. Hadoop includes two primary components: the Hadoop Distributed File System (HDFS), which stores data, and the MapReduce paradigm, which processes data. On the other hand, Spark is a comprehensive data processing system developed for speed and efficiency and to overcome the limitations of Hadoop, such as slow processing speed and lack of support for real-time processing.
Getting Started with Hadoop
Start learning Hadoop by getting yourself familiar with its system architecture. Next, install a version of Hadoop on your computer for hands-on practice. Several online platforms offer free resources, including step-by-step tutorials and videos that could benefit beginners. Learning about the HDFS and MapReduce is crucial to understanding how Hadoop stores and processes data. Finally, ensure you get hands-on experience handling data and running projects using Hadoop.
Getting Started with Spark
To start learning Spark, you must first understand Scala or Python, as Spark provides APIs in these languages. Install Spark on your system and get comfortable using Resilient Distributed Datasets (RDDs), which is the fundamental data structure of Spark. As with Hadoop, get hands-on experience by running simple tasks to understand how Spark processes data. Practice using Spark SQL for structured data processing and Spark Streaming for real-time data processing.
Learning Through Projects
After understanding Hadoop and Spark fairly, implement a few projects to gain practical knowledge. This could include data cleaning, extraction, analysis, or real-time data processing. Projects provide a practical understanding and increase your exposure to actual industry requirements. You can find project ideas from online resources or try to solve problems you face at work using these tools.
Continuous Learning and Improvement
Data science is a rapidly evolving field, and tools like Hadoop and Spark are also continuously improving. Therefore, you must continue learning new features and improvements in these tools. Following relevant blogs, attending webinars and conferences, and signing up for online courses can help you stay up-to-date with the latest developments.
Successfully transitioning into a proficient data scientist within 21 days is challenging. However, it’s not implausible. By meticulously embarking on the journey, fostering advanced expertise in math and statistics, programming languages like Python or R, diverse perspectives of machine learning, mastering big data processing tools, along with intensive practice in data wrangling and data visualization, one can forge an indelible imprint in the realm of data science. The journey might be demanding and strenuous, but your commitment to arduously exploring the depths of these domains will reap rewarding career dividends and surely position you as a vanguard in this compelling sphere. Stride confidently forward, relentlessly nurture your knowledge and skills, and become the data science expert you aspire to be.