
Understanding the needs and problems emerging from quantitative data analysis is crucial for driving objective, realistic and purposeful innovations across societal, private, government, or any other setup. Over the past few years, I have studied various publicly available datasets to drive or suggest innovation possibilities. The findings shared via this article here utilize k-means clustering analysis for a machine learning model focused on mental health to drive mental health inferences, interventions, and innovations based on publicly available data at Kaggle.com – containing over 40,000 records. To optimize processing time using Python on Google Colab, 25,000 records were randomly selected from the available dataset. This subset size proved optimal for completing the k-means clustering analysis within the processing capabilities available with my Google Colab subscription.
The k-means clustering method, an unsupervised learning technique, revealed three prominent clusters within the dataset. These clusters provide insights into appropriate mental health support strategies, interventions, and innovations based on various attributes such as age, education level, income, family history of depression, and more.
In k-means clustering, clusters represent groups of data points that are similar based on the features used in the analysis. Each cluster is defined by a centroid, which is the mean position of all the points in the cluster.
The primary goals of k-means clustering are:
- Minimize Variance Within Clusters: The algorithm aims to minimize the distance between data points and their respective centroids, resulting in tighter, more cohesive clusters.
- Maximize Variance Between Clusters: Clusters are formed so that the distance between the centroids of different clusters is as considerable as possible, ensuring that the clusters are distinct.
In summary, k-means clustering is about grouping data points that share similar characteristics. The goal is to achieve high intra-cluster similarity and low inter-cluster similarity, which are the primary goals of this clustering technique.
The results, although anticipated, show observable patterns as individuals progress through different life stages, validating these observations through the data and the ML model.
The following graph shows three prominent clusters after completing the following steps –
- Data encoding
- Data encoding in machine learning (ML) refers to the process of converting data into a specific format that can be effectively used by machine learning models and other ML algorithms. This step is crucial because raw data often cannot be directly fed into models, especially when dealing with categorical data, textual data, or complex structures like graphs and images.
- Z-Score scaling
- A z-score, also known as a standard score, measures the number of standard deviations a data point is from the mean of a data set. It is a way to standardize scores on a common scale, making it easier to compare data points from different distributions.
- Dimensionality reduction to two features (Feature 1 & Feature 2) for better visualization using t-SNE
- t-SNE (t-distributed Stochastic Neighbor Embedding) is a machine learning algorithm used for dimensionality reduction, specifically for the visualization of high-dimensional data.
- Finding optimal k (# of clusters) using Elbow and Silhouette Methods
- The elbow method is a technique used to determine the optimal number of clusters (k) in a k-means clustering algorithm. The goal is to find the value of k that best partitions the data into distinct clusters, balancing the trade-off between minimizing the variance within clusters and not having too many clusters.
- The Silhouette Method is another quantitative technique, than visual like elbow method, used to determine the optimal number of clusters in a clustering algorithm. It provides a measure of how similar an object is to its own cluster compared to other clusters. This method can be used to assess the quality of the clustering results.
- PS: For this analysis – I started with Elbow method and validated optimal k value with Silhouette method
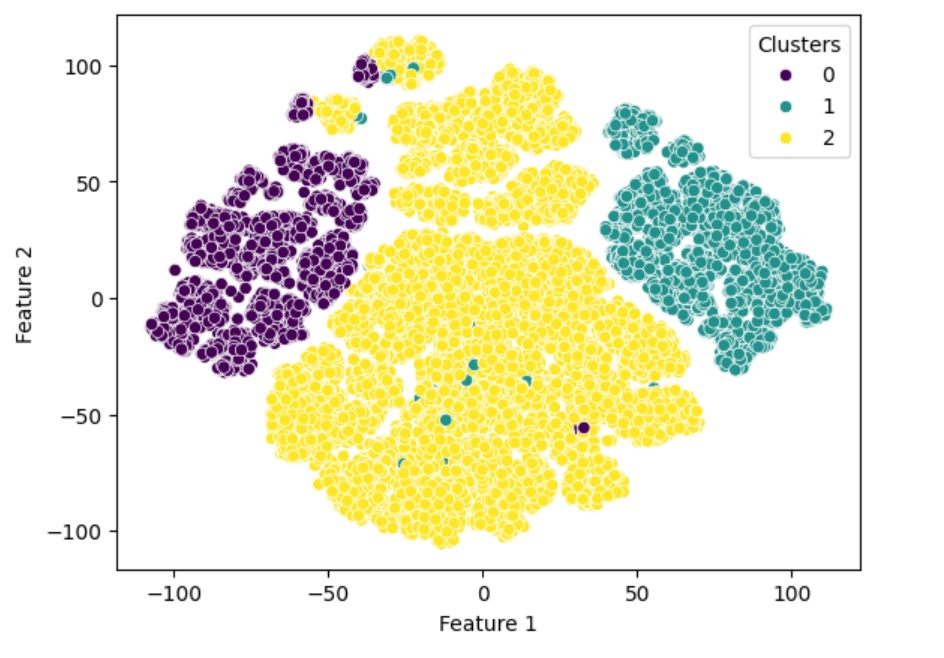
The dataset included the following key features:
- Marital Status: Single, Married, Divorced, Widowed
- Education Level: High School, Associate Degree, Bachelor’s Degree, Master’s Degree, PhD
- Number of Children: Number of children the individual has
- Smoking Status: Smoker, Former, Non-smoker
- Physical Activity Level: Sedentary, Moderate, Active
- Employment Status: Employed, Unemployed
- Income: Annual income in USD
- Alcohol Consumption: Low, Moderate, High
- Dietary Habits: Healthy, Moderate, Unhealthy
- Sleep Patterns: Good, Fair, Poor
- History of Mental Illness: Yes, No
- History of Substance Abuse: Yes, No
- Family History of Depression: Yes, No
- Chronic Medical Conditions: Yes, No
The graphs below shows the distribution of the clusters, with Cluster 2 being the largest. Further analysis could be conducted specifically on Cluster 2 for a deeper dive and potential sub-clustering
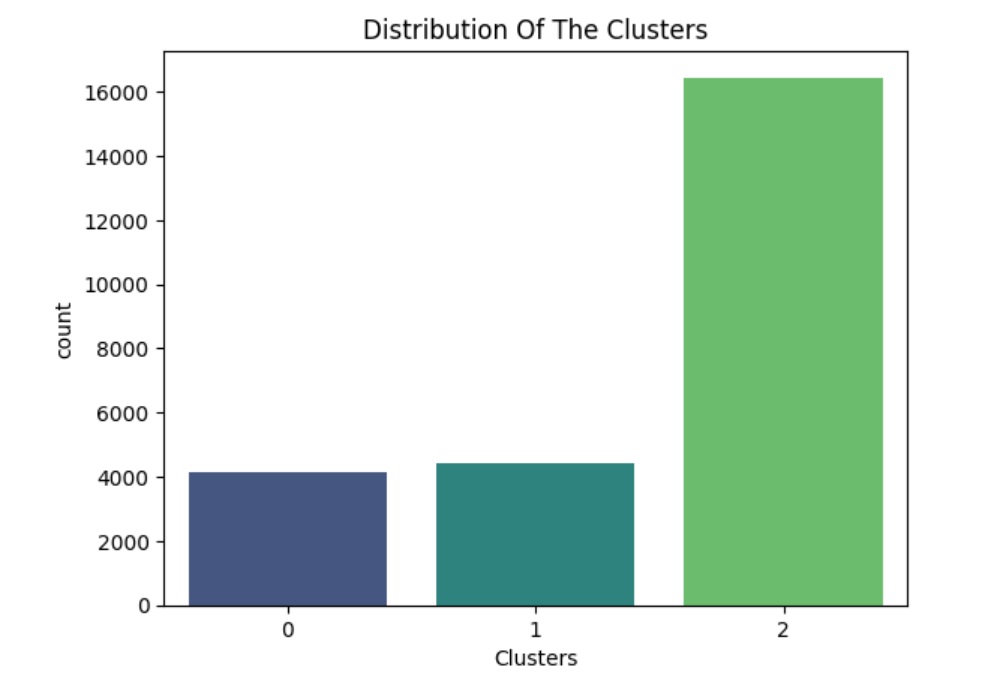
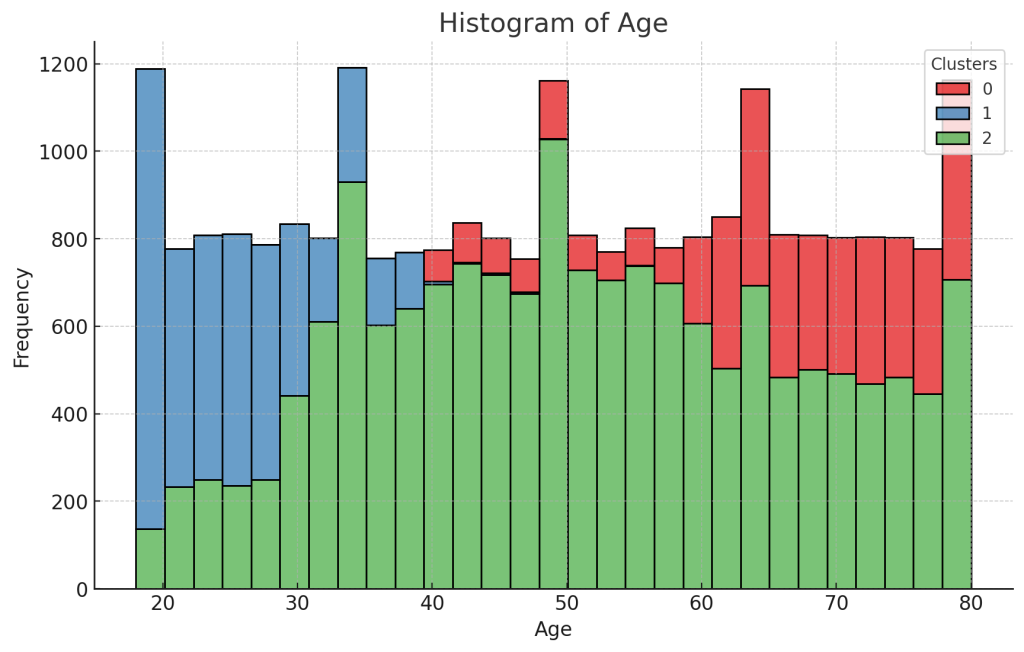
Summary of Insights from the Three Clusters
Cluster 0: Older Adults
- Age: The average age is 66 years.
- Number of Children: Typically have one child.
- Income: The average annual income is $46,396.33.
- Marital Status: 100% are widowed.
- Smoking Status: 68% are non-smokers.
- Physical Activity: 41% engage in moderate physical activity, while 55% are sedentary.
- Employment Status: 47% are unemployed.
- Alcohol Consumption: 42% consume alcohol moderately.
- Dietary Habits: 42% have unhealthy dietary habits.
- Sleep Patterns: 23% have poor sleep patterns.
- History of Mental Illness: 32% have a history of mental illness.
- History of Substance Abuse: 30% have a history of substance abuse.
- Family History of Depression: 50% have a family history of depression.
- Chronic Medical Conditions: 33% have chronic medical conditions.
Possible Inferences for this cluster
- High Risk of Isolation: Due to 100% being widowed, this cluster may experience significant isolation and loneliness.
- Health Concerns: A significant portion are sedentary, unemployed, and have chronic medical conditions, which can negatively impact their physical and mental health.
- Mental Health Focus: High rates of family history of depression and history of mental illness suggest a need for targeted mental health interventions.
Possible Innovations for this cluster
- Telehealth Services: Offering virtual consultations and mental health support.
- Wearable Technology: Devices to monitor physical activity and health parameters.
Cluster 1: Young Adults
- Age: The average age is 25 years.
- Number of Children: Typically have no children.
- Income: The average annual income is $48,963.52.
- Marital Status: 98% are single.
- Smoking Status: 51% are non-smokers.
- Physical Activity: 32% engage in moderate physical activity, while 24% are sedentary.
- Employment Status: 25% are unemployed.
- Alcohol Consumption: 41% consume alcohol moderately.
- Dietary Habits: 40% have unhealthy dietary habits.
- Sleep Patterns: 21% have poor sleep patterns.
- History of Mental Illness: 30% have a history of mental illness.
- History of Substance Abuse: 33% have a history of substance abuse.
- Family History of Depression: 20% have a family history of depression.
- Chronic Medical Conditions: 34% have chronic medical conditions.
Possible Inferences for this cluster
- High Stress and Mental Health Concerns: The age group and significant percentage of single individuals may indicate high stress related to career and personal life.
- Moderate Physical Activity and Employment: Physical activity levels and employment status suggest a generally active lifestyle, but there is room for improvement in physical activity and reducing unemployment.
- Mental Health Awareness: Given the history of mental illness and substance abuse, mental health awareness and support programs are crucial.
Possible Innovations for this cluster:
- Mental Health Apps: Accessible mental health resources and meditation apps.
- Flexible Work Arrangements: Promoting work-life balance through remote working options.
Cluster 2: Middle-Aged Adults
- Age: The average age is 51 years.
- Number of Children: Typically have two children.
- Income: The average annual income is $52,222.62.
- Marital Status: 88% are married.
- Smoking Status: 60% are non-smokers.
- Physical Activity: 39% engage in moderate physical activity, while 44% are sedentary.
- Employment Status: 36% are unemployed.
- Alcohol Consumption: 42% consume alcohol moderately.
- Dietary Habits: 41% have unhealthy dietary habits.
- Sleep Patterns: 36% have poor sleep patterns.
- History of Mental Illness: 30% have a history of mental illness.
- History of Substance Abuse: 31% have a history of substance abuse.
- Family History of Depression: 23% have a family history of depression.
- Chronic Medical Conditions: 33% have chronic medical conditions.
Possible Inferences for this cluster
- Balancing Family and Work: The presence of children and high marriage rates suggest that balancing family and work responsibilities could be a significant stressor.
- This is also the time when many people start to lose their parents and potentially other individuals they looked up to throughout their lives.
- Health and Activity: A mixed level of physical activity and high rates of unhealthy dietary habits suggest the need for health and wellness programs.
- Mental Health and Chronic Conditions: Similar rates of mental illness and chronic medical conditions as other clusters indicate a need for comprehensive health care.
Possible Innovations for this cluster
- Digital Health Platforms: Comprehensive platforms for managing health and wellness.
- Employee Assistance Programs: Offering mental health resources and support at the workplace.
General Recommendations
- Tailored Interventions: Each cluster requires tailored mental health and wellness programs based on their specific characteristics and needs.
- Community Support: Encouraging community support and engagement can significantly benefit all clusters, particularly the older adults.
- Physical Activity and Healthy Habits: Promoting physical activity and healthy dietary habits can improve overall well-being across all clusters.
- Mental Health Services: Access to mental health services and support is critical, especially for clusters with a high history of mental illness and substance abuse.
Societal Considerations
- Customized Interventions: Tailoring mental health programs based on the specific needs of each cluster.
- Holistic Health Approaches: Integrating physical, mental, and social health initiatives.
- Community-Based Programs: Leveraging community resources to support mental health and well-being.
- Technology Integration: Utilizing digital tools and platforms to provide accessible mental health support.
This isn’t an exhaustive analysis, and there are numerous other factors to consider when understanding and improving mental health. However, AI and ML techniques are poised to make a significant impact on mental health diagnosis and related innovations, ultimately enhancing the quality of life for many patients.

